Projects
In this page you can find a list of my most important projects, related with even my educational life (my career) or my work life.
Product Recommender with Chatbot (2018)
In my 4 years of college I've done many projects of any kind. One of the most challenging ones was developing a Chatbot able to list your supermarket items and make suggestions about them. The Chatbot was made with Telegram, due to that his API is tremendously simple and easy-to-learn. The algorithm behind the recommender logic was initially done with the Apriori algorithm, but later on was upgraded with an approximation of the Page-Rank algorithm. You can check the project in my public repository.
Detecting discrimination trough Suppes-Bayes Causal Network (2019)
Developed with Eurecat, this project was part of my bachelor thesis. The idea was to develop a tool that would combine two lines of work: the internal representation of the data, with an entry in the database representing a person and all its attributes, and mathematical problems based on assessing risks of reidentification or discrimination of an individual based on their characteristics.
Starting with the techniques given in the paper "Exposing the probabilistic causal structure of discrimination", I developed an algorithm that allowed the extraction of graphical probabilistic models that after being trained by likelihood-fit they transform into a Suppes-Bayes Causal Networks (SBCN). The generated SBCN could be exploited with random walk methods that provided information about the presence of discrimination and its level, if any.
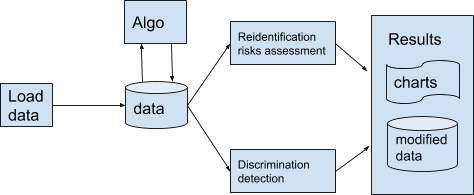
Once I had the algorithm working I designed and deployed a fully-functional website that enabled any user to upload their dataset and extract all the information that my algorithm provided in a visual and easy-to-understand way.
The 100% of this project code is open-sourced and open for any future extension. My 80-page paper is also available for everyone, but I also made a small and simple presentation so you don't have to read it all 🤓.
Accuracy comparison in high-dimensional product sales forecasting with inter-product relationships and promotions (2021)
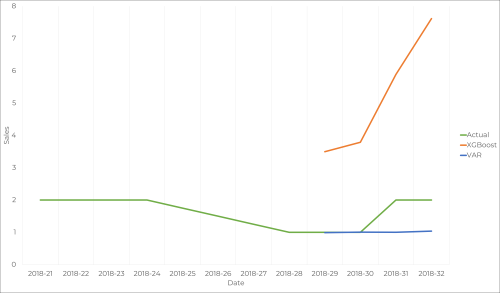
Developed alongside Accenture, the aim of this project was the comparison between a modified Vector Autoregressive model, specialized in detecting product relationships, and a Machine Learning traditional model, XGBoost, developed by Accenture. I built a framework able to pre-process, adapt, train and compare and evaluate both models, using Python and R.
The conclusions of my work were based on accuracy results using more than 4 forecast evaluation metrics and promotion & product relationships associations. The XGBoost implementation remains private since it was developed by Accenture. You can take a look at the thesis report for further explaination.